Spark persist不生效
在跑任务的过程中,有一个RDD需要用到两次,所以我们手动调用了persist()函数,但是发现第二次用这个RDD的时候,还是重新计算了一遍。
在Spark UI的Storage页面中,我们发现这个RDD并没有被完全Cache下来,可能是完全Cache下来的话,需要的资源太多。如下图所示:
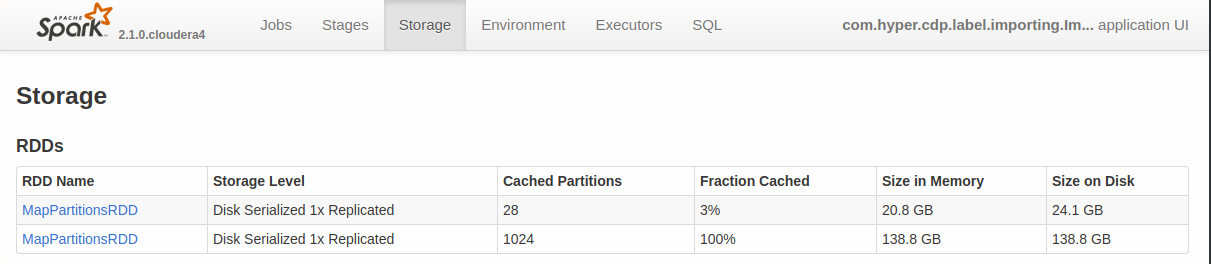
想想也非常合理,如果缓存不下来,就会重新计算这个RDD.
这也提醒我们,调用persist函数有代价,一是RDD再次被用到的时候,还是可能重新计算,二是如果RDD过大,还占用了大量内存。