在前面一篇文章中,我们讲到了ResourceManager,NodeManager以及ApplicationMaster的职责,以及它们的工作流程。
我们提到了,ApplicationMaster会通过向ResourceManager发送ResourceRequest这个数据结构,来获得Container,然后再联系对应的NodeManager进行Container的启动。
我们也提到了,ResourceRequest这个数据结构中,包含了一个属性Resource location,这个属性指定了我们期望在哪个节点分配Container。
那我们这儿就有一个问题了,是ApplicationMaster提前确定好,要在哪个DataNode上分配Container,来做到Container和Data在同一台机器上么?如果是这个样子,那如果这台机器上没有资源了,那ApplicationMaster还需要再选择一台DataNode,再去分配,这样岂不是增多了RPC的数量,而且显得特别繁琐。
那如果ApplicationMaster先在这个Mapper对应的InputSplit的全部的Hosts上分配Container,然后根据返回的信息,从中选择一个DataNode,先选择和Block位于同一台机器的Container,如果没有,那么选择位于同一机架的Container,如果这还没有,再随便选择一个就好了。如果采用这种方法呢?
这种方法虽然有效减少了RPC的数量,但是我们考虑一个极端场景。
假设有两个Application,我们分别称呼它们为Application1和Application2。假设Application1是压死这个集群的最后一根稻草,即ApplicationMaster1联系ResourceManager分配Container以后,这个集群中就没有任何剩余的资源可以再分配Application2了。此时,ApplicationMaster2也联系ResourceManager来请求资源,此时ResourceManager只能告诉它,”对不起,我们这儿没有资源了”。
Application2会自动重试还是会直接报错,这个我不太清楚,没看。
而其实Application1申请了那么多的Container,它其实并没有用到。假设有n个Mapper,每个block有m个replicas,那就需要申请n*m个Container,而其实最终能被用到的只有n个。
而ApplicationMaster会给每个Mapper尽量选择一个和block位于同一台Host的Container,即对于每个InputSplit,都是从m中选择一个。这里需要注意InputSplit和Mapper是一一对应的。当全部的Mapper都选择了合适的Container以后,就会联系ResourceManager,取消多分配的Container.
在YARN中,就是采用这种方法来给Mapper分配Container,也正是通过这种方式,来保证了尽量在数据本地节点分配Task.
尽管存在上面的极限情况,但是这个毕竟影响不大。而且,从YARN的源码中,可以看到,它是想方设法尽量少发送RPC的。
先贴流程图:
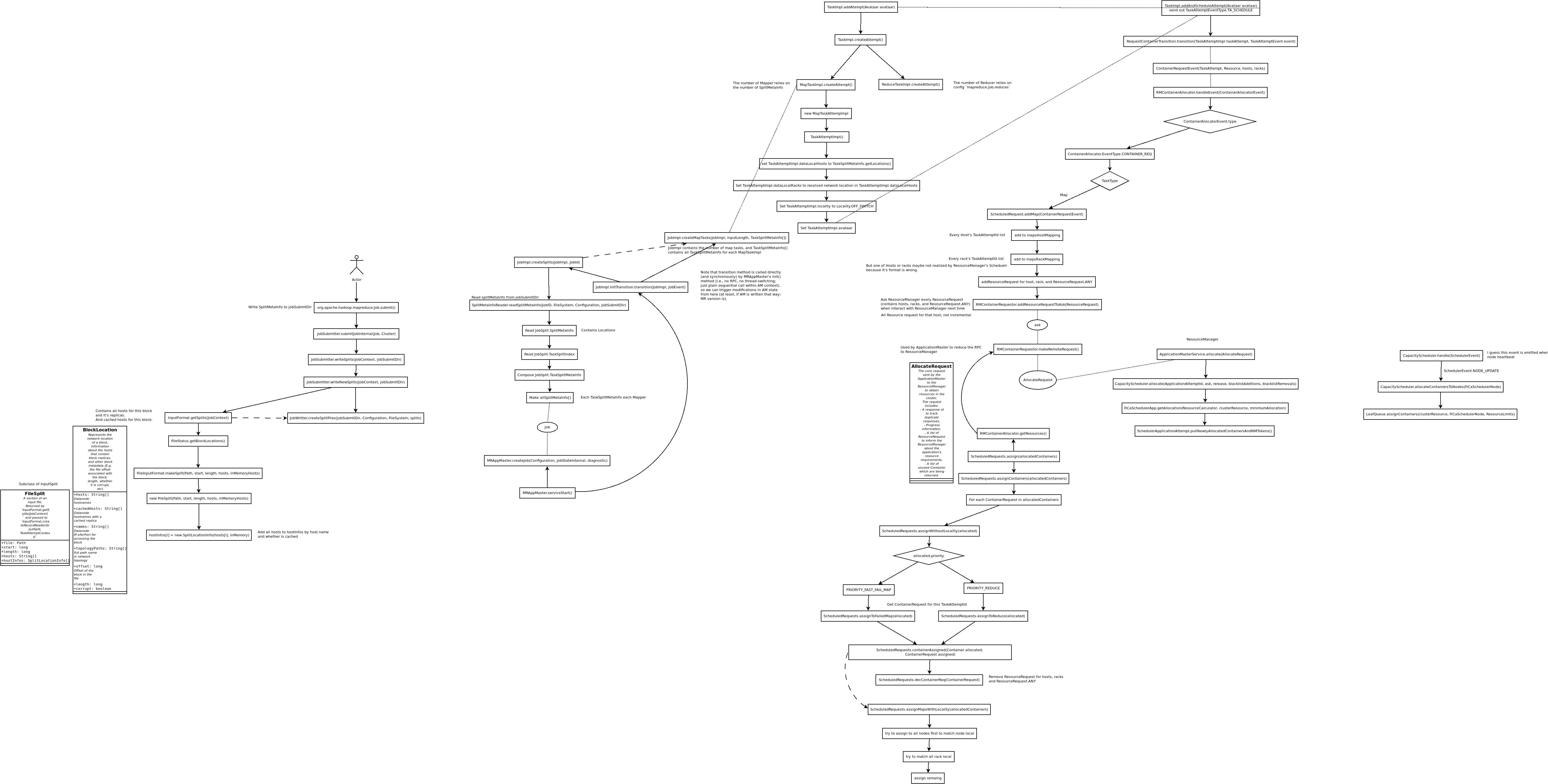
下面简单介绍一下源码。
首先,当我们调用Job.submit()的时候,它会生成InputSplit,然后写到一个目录中去。
JobSubmitter.writeNewSplits(JobContext job, Path jobSubmitDir):
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
注意这里的InputSplit包含了这个block全部replicas所在的hosts,不是只有一个。
然后ApplicationMaster启动起来以后呢,会从上面的这个目录中,读取对应的InputSplit信息,并形成TaskSplitMetaInfo.
SplitMetaInfoReader.readSplitMetaInfo(JobID, FileSystem, Configuration, Path):
public static JobSplit.TaskSplitMetaInfo[] readSplitMetaInfo(
JobID jobId, FileSystem fs, Configuration conf, Path jobSubmitDir)
throws IOException {
long maxMetaInfoSize = conf.getLong(MRJobConfig.SPLIT_METAINFO_MAXSIZE,
MRJobConfig.DEFAULT_SPLIT_METAINFO_MAXSIZE);
Path metaSplitFile = JobSubmissionFiles.getJobSplitMetaFile(jobSubmitDir);
String jobSplitFile = JobSubmissionFiles.getJobSplitFile(jobSubmitDir).toString();
FileStatus fStatus = fs.getFileStatus(metaSplitFile);
if (maxMetaInfoSize > 0 && fStatus.getLen() > maxMetaInfoSize) {
throw new IOException("Split metadata size exceeded " +
maxMetaInfoSize +". Aborting job " + jobId);
}
FSDataInputStream in = fs.open(metaSplitFile);
byte[] header = new byte[JobSplit.META_SPLIT_FILE_HEADER.length];
in.readFully(header);
if (!Arrays.equals(JobSplit.META_SPLIT_FILE_HEADER, header)) {
throw new IOException("Invalid header on split file");
}
int vers = WritableUtils.readVInt(in);
if (vers != JobSplit.META_SPLIT_VERSION) {
in.close();
throw new IOException("Unsupported split version " + vers);
}
int numSplits = WritableUtils.readVInt(in); //TODO: check for insane values
JobSplit.TaskSplitMetaInfo[] allSplitMetaInfo =
new JobSplit.TaskSplitMetaInfo[numSplits];
for (int i = 0; i < numSplits; i++) {
JobSplit.SplitMetaInfo splitMetaInfo = new JobSplit.SplitMetaInfo();
splitMetaInfo.readFields(in);
JobSplit.TaskSplitIndex splitIndex = new JobSplit.TaskSplitIndex(
jobSplitFile,
splitMetaInfo.getStartOffset());
allSplitMetaInfo[i] = new JobSplit.TaskSplitMetaInfo(splitIndex,
splitMetaInfo.getLocations(),
splitMetaInfo.getInputDataLength());
}
in.close();
return allSplitMetaInfo;
}
读出来以后呢,就开始创建TaskAttemptImpl,设置它的dataLocalHosts以及dataLocalRacks,其中dataLocalHosts就是TaskSplitMetaInfo中,此Split对应的block的全部的replicas的Hosts,dataLocalRacks就是这些Hosts所在的机架.
TaskAttemptImpl constructor:
public TaskAttemptImpl(TaskId taskId, int i,
EventHandler eventHandler,
TaskAttemptListener taskAttemptListener, Path jobFile, int partition,
JobConf conf, String[] dataLocalHosts,
Token<JobTokenIdentifier> jobToken,
Credentials credentials, Clock clock,
AppContext appContext) {
oldJobId = TypeConverter.fromYarn(taskId.getJobId());
this.conf = conf;
this.clock = clock;
attemptId = recordFactory.newRecordInstance(TaskAttemptId.class);
attemptId.setTaskId(taskId);
attemptId.setId(i);
this.taskAttemptListener = taskAttemptListener;
this.appContext = appContext;
// Initialize reportedStatus
reportedStatus = new TaskAttemptStatus();
initTaskAttemptStatus(reportedStatus);
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
readLock = readWriteLock.readLock();
writeLock = readWriteLock.writeLock();
this.credentials = credentials;
this.jobToken = jobToken;
this.eventHandler = eventHandler;
this.jobFile = jobFile;
this.partition = partition;
//TODO:create the resource reqt for this Task attempt
this.resourceCapability = recordFactory.newRecordInstance(Resource.class);
this.resourceCapability.setMemory(
getMemoryRequired(conf, taskId.getTaskType()));
this.resourceCapability.setVirtualCores(
getCpuRequired(conf, taskId.getTaskType()));
// Resolve ip to host name
this.dataLocalHosts = resolveHosts(dataLocalHosts);
RackResolver.init(conf);
this.dataLocalRacks = new HashSet<String>();
for (String host : this.dataLocalHosts) {
this.dataLocalRacks.add(RackResolver.resolve(host).getNetworkLocation());
}
locality = Locality.OFF_SWITCH;
avataar = Avataar.VIRGIN;
// This "this leak" is okay because the retained pointer is in an
// instance variable.
stateMachine = stateMachineFactory.make(this);
}
然后就会给ResourceManager发送AllocateRequest,请求分配Container.注意,这儿并不是每个InputSplit只在一台Host上分配,而是在全部这个InputSplit所在的block的全部的hosts上分配Container.
然后ResourceManager检查对应的Scheduler策略,是否有足够的资源可用,并返回给ApplicationMaster。这儿就不上代码了。
需要注意的是,ApplicationMaster给ResourceManager发送哪些请求,ResourceManager就给ApplicationMaster返回哪些。它并不负责,对每个InputSplit,尽量选择一台Host,保证Container和block位于同一台机器上。它只是检查并分配资源而已,让Container和block位于同一节点,是ApplicationMaster的工作。
ApplicationMaster在拿到这些Container以后,从中选择和block位于同一主机的Container并通知ResourceManager取消其它无用的Container.
ScheduledRequests.assignMapsWithLocality(allocatedContainers):
private void assignMapsWithLocality(List<Container> allocatedContainers) {
// try to assign to all nodes first to match node local
Iterator<Container> it = allocatedContainers.iterator();
while(it.hasNext() && maps.size() > 0 && canAssignMaps()){
Container allocated = it.next();
Priority priority = allocated.getPriority();
assert PRIORITY_MAP.equals(priority);
// "if (maps.containsKey(tId))" below should be almost always true.
// hence this while loop would almost always have O(1) complexity
String host = allocated.getNodeId().getHost();
LinkedList<TaskAttemptId> list = mapsHostMapping.get(host);
while (list != null && list.size() > 0) {
if (LOG.isDebugEnabled()) {
LOG.debug("Host matched to the request list " + host);
}
TaskAttemptId tId = list.removeFirst();
if (maps.containsKey(tId)) {
ContainerRequest assigned = maps.remove(tId);
containerAssigned(allocated, assigned);
it.remove();
JobCounterUpdateEvent jce =
new JobCounterUpdateEvent(assigned.attemptID.getTaskId().getJobId());
jce.addCounterUpdate(JobCounter.DATA_LOCAL_MAPS, 1);
eventHandler.handle(jce);
hostLocalAssigned++;
if (LOG.isDebugEnabled()) {
LOG.debug("Assigned based on host match " + host);
}
break;
}
}
}
// try to match all rack local
it = allocatedContainers.iterator();
while(it.hasNext() && maps.size() > 0 && canAssignMaps()){
Container allocated = it.next();
Priority priority = allocated.getPriority();
assert PRIORITY_MAP.equals(priority);
// "if (maps.containsKey(tId))" below should be almost always true.
// hence this while loop would almost always have O(1) complexity
String host = allocated.getNodeId().getHost();
String rack = RackResolver.resolve(host).getNetworkLocation();
LinkedList<TaskAttemptId> list = mapsRackMapping.get(rack);
while (list != null && list.size() > 0) {
TaskAttemptId tId = list.removeFirst();
if (maps.containsKey(tId)) {
ContainerRequest assigned = maps.remove(tId);
containerAssigned(allocated, assigned);
it.remove();
JobCounterUpdateEvent jce =
new JobCounterUpdateEvent(assigned.attemptID.getTaskId().getJobId());
jce.addCounterUpdate(JobCounter.RACK_LOCAL_MAPS, 1);
eventHandler.handle(jce);
rackLocalAssigned++;
if (LOG.isDebugEnabled()) {
LOG.debug("Assigned based on rack match " + rack);
}
break;
}
}
}
// assign remaining
it = allocatedContainers.iterator();
while(it.hasNext() && maps.size() > 0 && canAssignMaps()){
Container allocated = it.next();
Priority priority = allocated.getPriority();
assert PRIORITY_MAP.equals(priority);
TaskAttemptId tId = maps.keySet().iterator().next();
ContainerRequest assigned = maps.remove(tId);
containerAssigned(allocated, assigned);
it.remove();
JobCounterUpdateEvent jce =
new JobCounterUpdateEvent(assigned.attemptID.getTaskId().getJobId());
jce.addCounterUpdate(JobCounter.OTHER_LOCAL_MAPS, 1);
eventHandler.handle(jce);
if (LOG.isDebugEnabled()) {
LOG.debug("Assigned based on * match");
}
}
}
从上述代码中,我们可以看到,ApplicationMaster和ResourceManager的交互,都是通过batch-RPC的方式进行的。也就是,并不是每次要分配一个Container,就告诉ResourceManager进行分配,而是攒在一起,最后通过batch的方式发送。